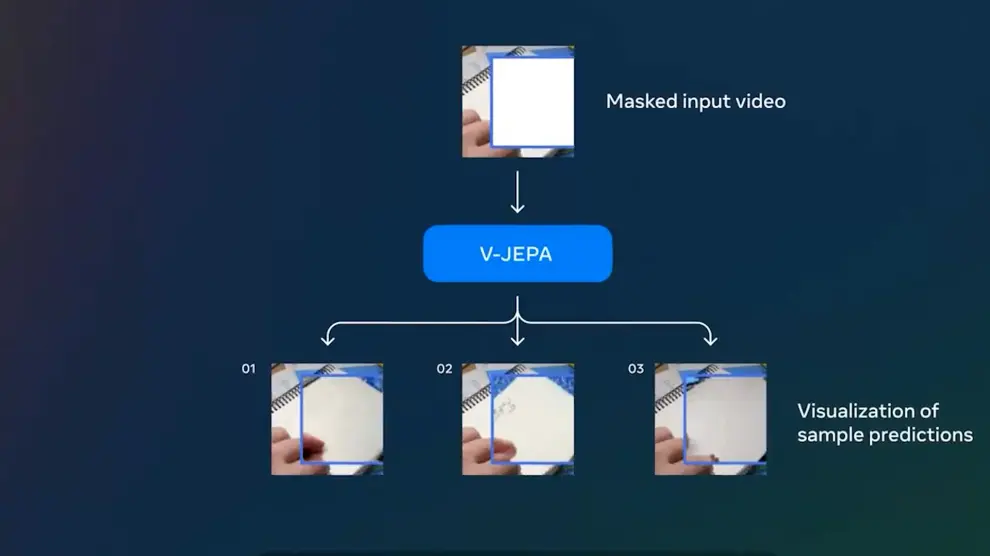
Meta presenta V-JEPA, un modelo predictivo que aprende mediante la visualización de vídeos
Meta ha presentado un nuevo modelo no generativo desarrollado para enseñar a las máquinas a comprender y modelar el mundo físico mediante la visualización de vídeos. El nuevo modelo, que recibe el nombre de Video Joint Embedding Predictive Architecture (V-JEPA), aprende a realizar tareas prediciendo partes perdidas o enmascaradas de un vídeo en un espacio de representación abstracto.
MÁS VÍDEOS RELACIONADOS





